

This article is the second in our "How Akka Works" series that dives into some of the interesting aspects of messaging within distributed systems environments. While the particular focus of these articles covers messaging within an Akka distributed actor systems, the concepts covered here also apply to messaging within other distributed systems, such as messaging within microservice systems. In this part, we take a look at at-most-once messaging. You can jump to Part 1: At Most Once and Part 3: Exactly Once of this series to review the other messaging patterns we cover, as well as check the Message Delivery Reliability documentation provided on the Akka website.
In Part 1 of this three-part series, we discussed the mechanics of at-most-once message delivery. In part 2 we are going to look at what is called at-least-once message delivery. Finally, in part 3 we will look at exactly-once message delivery.
While we are in the middle of this series of the three types of message delivery, it is a good time to review and contrast all three approaches.
As we briefly review the semantics of each of these message delivery approaches, we will look at this from the perspective of both message senders and message receivers.
As discussed in some detail in part 1, the at-most-once message delivery approach means that when sending a message from a sender to a receiver there is no guarantee that a given message will be delivered. Any given message may be delivered once or it may not be delivered at all. Any attempt to deal with a failure to deliver a message is crossing into the at-least-once message delivery territory.
This maybe-once delivery approach is analogous to you sending a message via a text message or letter using the postal service. In either case, once you send the text or post the letter you do not attempt to verify that the message was delivered to me. Using the at-most-once approach for message delivery is acceptable in many cases, especially in situations where the occasional lose of a message does not leave a system in an inconsistent state.
With the at-least-once approach for sending messages either the message sender or the message receiver or both actively participate in ensuring that every message is delivered at least once. To ensure that each message is delivered either the message sender must detect message delivery failures and resend upon failure, or the message receiver must continuously request messages that have not been delivered. Either the message sender is pushing each message until the message receiver acknowledges that the message was received, or the message receiver is pulling undelivered messages.
Why do we have at-least-once when exactly-once seems to be a much better solution? To answer this question, we need to look at some of the basic mechanics of messaging.
Consider this scenario. You and I are exchanging text messages. I need to send you an urgent text message. I send you this urgent text message and to ensure that you have received it I’m expecting an acknowledgment response text message from you.
The ideal sequence of events is that I send you this urgent text message, you read it, and then you send me an acknowledgment text message that lets me know that you have received my message.
This is the happy path where everything works as expected. However, there is also the sad path where something occurs that prevents this exchange of text messages from happening as we expected.
The fundamental challenge here is that when I do not receive an acknowledgment from you, I have no way of determining if you have received the message. Multiple failure scenarios will happen that result in the failure to receive an acknowledgment message. One of the failure scenarios is that you did receive the urgent text message but were unable to send me an acknowledgment. From my perspective, there is no way for me to know if you did or did not received the message. As a result, I am forced to resend the urgent text message again and again until I hear back from you. Also, as a result, you may receive my message more than once.
This at-least-once delivery process is what we are going to examine in more detail in this post.
As we just briefly discussed, with the at-least-once messaging approach, the best we can do is implement processes that may result in the delivery of some messages more than once.
Conceptually an exactly-once message approach is much more desirable. But, as the saying goes, “you can’t always get what you want.”
For now, consider that implementing an exactly-once messaging solution is on the same level as creating a vehicle that can travel faster than the speed of light. There are ways to get close, that is to deliver messages essentially-once but it is impossible to implement an exactly-once process that works. In part 3 of this series, we will look at this in more detail.
Let’s walk through a typical exchange of messages between a message sender and a message receiver. As shown in Figure 1, there are at least four distinct steps in the message request and response cycle.

1) Send a request message across the network from the sender to the receiver. 2) The message receiver reacts in some way to the request message. 3) The message receiver sends a response message over the network to the sender. 4) The message sender reacts to the response message.
In this request to response journey, multiple things will, at some point, go wrong. Various failures will occur at each of the four steps.
To start, as shown in Figure 2, network issues will prevent the transmission of request messages to the receiver.

In Figure 3 failures are shown that occur after the request message has arrived and while it is being processed during the request reaction step. Failures at this second stage are typically caused by process, container, or node failures.

Once request messages have been processed in the third step response messages are transmitted across the network back to the sender. Once again, as shown in Figure 4, network failures will prevent these messages from being sent.

Finally, when response messages arrive back at the initial sender failures at this stage will prevent the completion of the full cycle of processing, as shown in Figure 5.

From the perspective of the message sender, any one of these failures will indicate that something went wrong, but when failures do occur, it is impossible to know if the message receiver reacted to the message or not. Also, consider the failure scenario at stage 4. The message sender has received a response message, but it failed before it properly handle the response. When the sender is restarted there is no evidence that a response was received. Again, from the perspective of the message sender, it is as if the initial request message was not sent.
When failures do occur, the sender has no choice but to send the message again. As we can now see depending on where in the sequence a failure did happen there is the possibility that the same messages will be sent multiple times to the receiver.
With messaging our intuition often leads us to think of the message delivery process as the message producer actively sending messages to the message consumer. It is also common that we implement methods that work very well for the happy path but that are brittle or inadequate for the sad path.
Also, in some cases, it is ok that some messages are lost and never delivered. It is simply not worth the effort to harden the messaging process to a level where every single message is delivered, and no messages are lost. So the choice comes down to at-most-once or at-least-once.
Our intuition and feeling that reliable message delivery is too hard or not worth the effort often results in the implementation of relatively simple push oriented message delivery approaches, such as the well known RESTful interface approach.
In some cases, the simple approach is perfectly acceptable. However, in other instances implementing a system that will at times drop messages is unacceptable.
Fortunately, there are at least two ways to implement message delivery processes that guarantee at-least-once delivery of every single message. There is a push approach and a pull approach. As the name implies, with the push approach, the message producer pushes messages to message consumers. The alternative is the pull approach where the message consumer pulls messages from the message producer.
With the push approach, the burden of responsibility for at-least-once message delivery falls on the message producer. Let’s use person to person texting as an example again to explore the mechanics of the process.
Consider the case where you are trying to send a message that must be delivered to me, and there is a problem that is preventing the successful delivery of that message. Ok, one of the first things that you can do is implement a retry loop, as shown in Figure 6, where you retry the delivery of unacknowledged messages until you have confirmation that they have been delivered to the receiver.

That should work, right? Well, you need to ask yourself what can go wrong? Hold on, let’s restate that - you need to ask yourself what WILL go wrong? When you are designing for reliability you must face facts; things will break. Software, servers, and networks will fail. And some of these failures will happen at the worst possible time. Like when one or more undelivered messages are currently stuck in a retry loop.
Given that it is bad if you go down while undelivered messages are stuck in a retry loop you need to do something that will prevent the loss of undelivered messages in the event of a failure of the message producer. One solution is first to place all to be delivered messages into a persistent list or queue before you try to send each message to the receiver.
Now that you have a persistent place to store undelivered messages do you have a solid design? Not really. Consider that something had to happen that triggered the need to send a message in the first place. In our texting example, say that you performed some task that triggered the need for you to send me a message.
Say you are keeping a journal that records all of the people that you are tasked with sending these urgent must be delivered text messages. The result is that each time you receive a request to send someone a text message you first record this task in your journal, and then you add the pending message to the list of to be sent messages. In a software implementation of this process, this would be implemented as two distinct database transactions, as shown in Figure 7, one transaction that adds a task to a journal and second transaction that adds the message to a persistent list or queue.
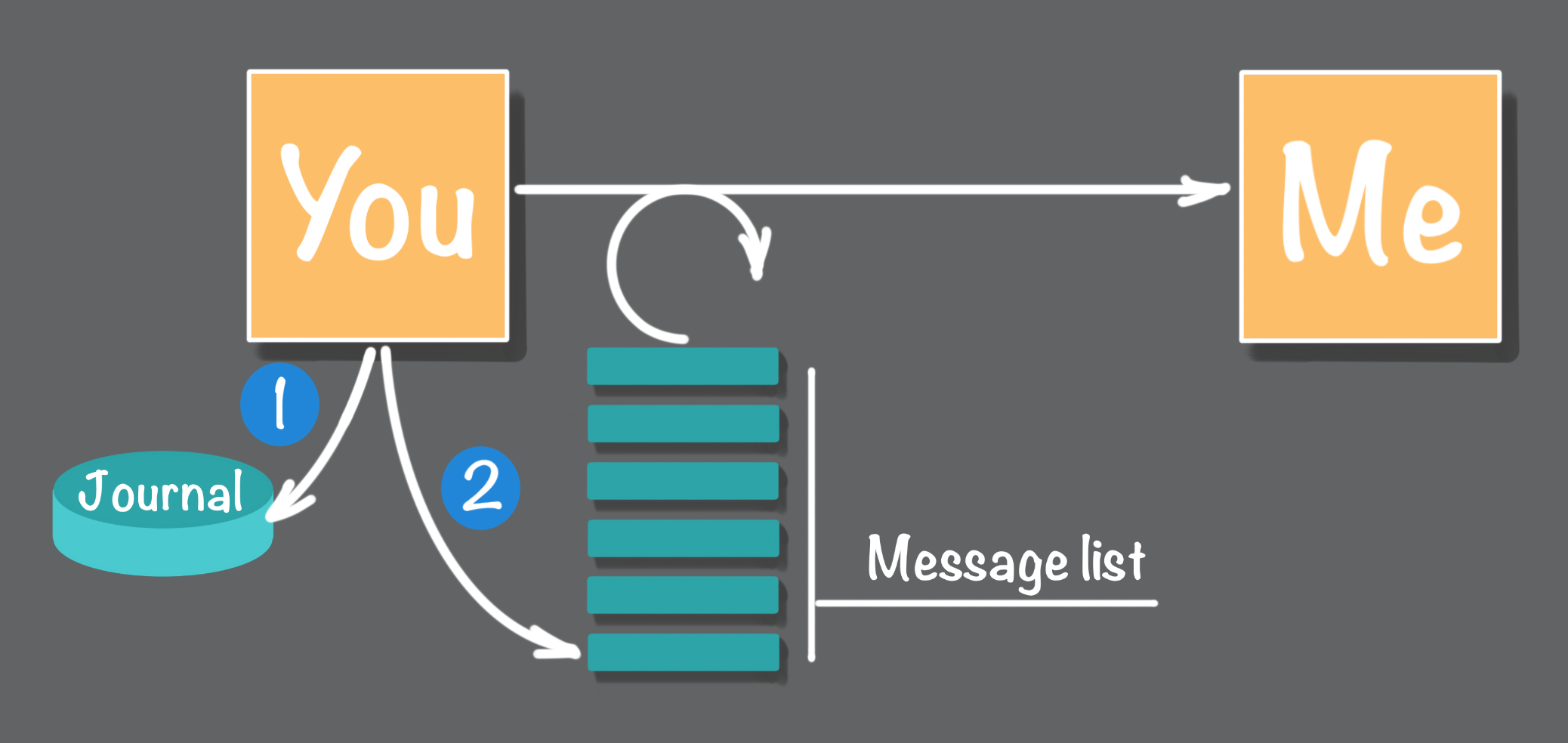
Ok, now you have this two-step process that records tasks in a journal and adds the corresponding message to a to be delivered list. Are there any vulnerabilities here? What will go wrong?
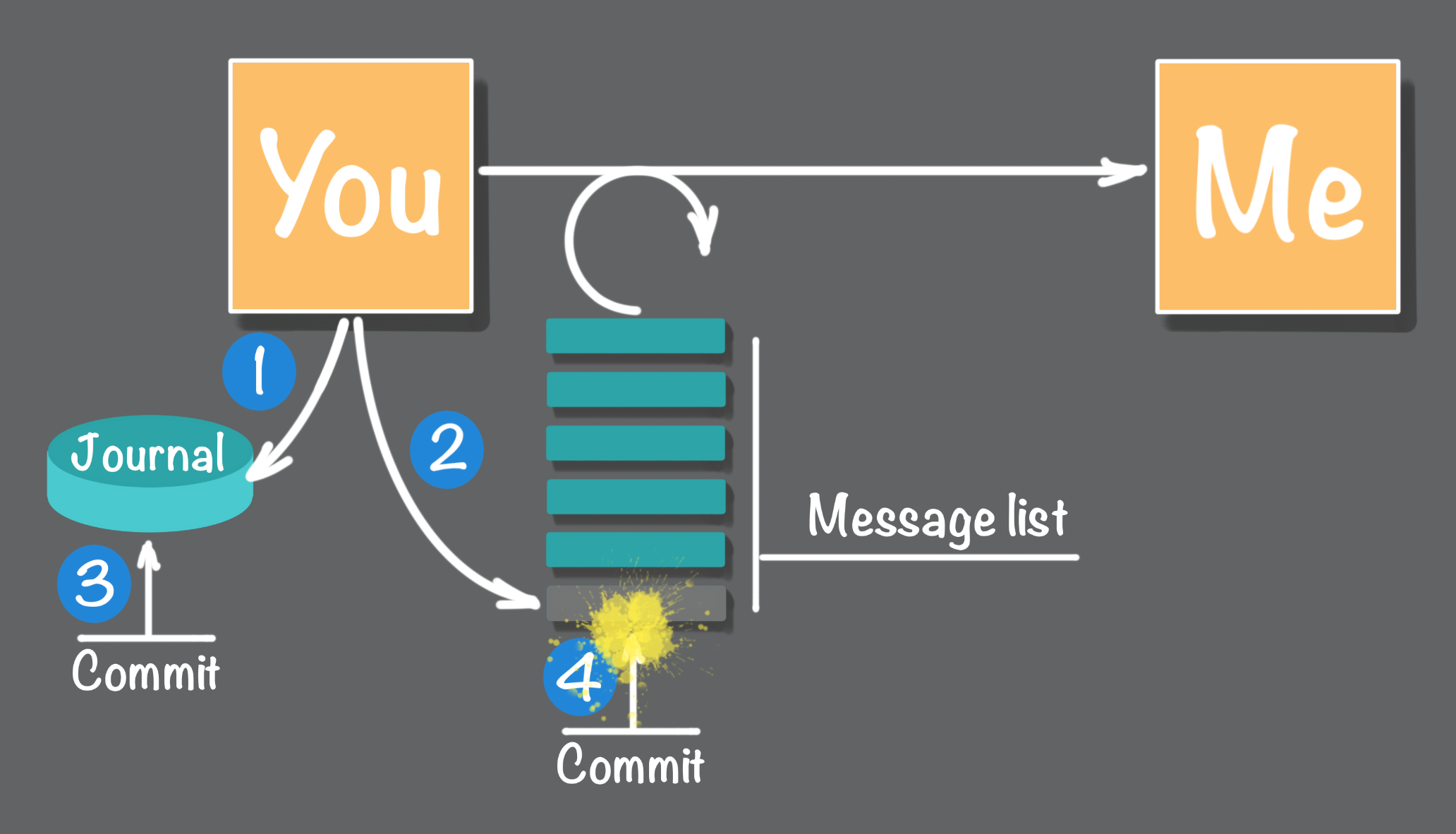
There is a vulnerability. This is a two-step process. In a software implementation, two distinct atomic transactions happen one after the other. Any interruption that occurs after the first transaction is completed but before the second transaction is committed results in the loss of adding the message to the list. Effectively the message is lost, as shown in Figure 8.

How do we fix this problem? In the manual approach after any interruption, it would be necessary to scan the journal for any missing entries in the to be delivered message list. In software, one possibility would be to combine these two steps into a single database transaction. However, this may not be technically doable. For example, if the journal resides in a relational database the message list resides in a queue there is no way to combine these two operations into a single transaction. The best you could do is to overlap both transactions, shown in Figure 9, and commit them one after another, but as shown in Figure 9, there is still a window of vulnerability between the completion of the first and second commit.
Another software approach would be to implement some form of housekeeping at startup. Just as we discussed with the manual example, during the housekeeping phase a scan is done of the journal and the list looking for missing messages in the list or queue.
At this point you may be asking yourself is all of this additional reliability worth the effort? What are the odds of problems occurring when failures do occur?
With any software implementation, you sometimes have to consider the tradeoffs. In this push example, things are starting to get pretty complicated. We went from a comparatively simple at-least-once RESTful approach with a probability of a reasonable number of nines in the message delivery reliability %99.9…9 range to an increasingly complex implementation to get a 100% solution. In the case where the task journal and the pending messages list can be handled with a single transaction you do have a at-least-once solution. Things are even better when you can use the task journal as the pending message list. This combined approach will be covered later in part 3.
The dilemma is that if you do weigh the odds and make the call to compromise on the reliability of message delivery than you have effectively and deliberately decided to introduce bugs into your implementation. Ultimately you have to make the decision here. In this case, if you do compromise you must consider that problems will occur in the future that may be inherited by others or may come back to haunt you. Also, consider that dropping the occasional message is a relatively subtle bug that will be hard to detect and may be even harder to fix.
Fear not. There are ways to implement more reliable message delivery processes. One approach that is often much less complicated to implement is the somewhat counterintuitive pull approach. This is what we will be looking at in the next section.
With the pull approach, we still have a message sender or producer, and we also have a message receiver or consumer. However, the actual process that is used to transmit messages from the producer to the consumer is flipped. Instead of the message producer actively pushing messages to the consumer, it is the consumer that assumes the primary responsibility for retrieving messages from the producer.
For implementations of the pull approach, the message producer’s primary responsibility is to place all messages in a list or log. The consumer’s responsibility is to maintain a pointer or offset into the producer’s log that identifies the next message to be transmitted and processed. As the producer is consuming messages, shown in Figure 10, the offset is incremented to the next message.

The next message pointer or offset must be managed in a way so that when the consumer is restarted the current value of the offset can be recovered, which requires that the offset is persisted.
In the case where the message consumer is performing persistent state changes when processing messages, an important consideration is the combination of the step for persisting the state change and the step for persisting the current offset. Ideally, both of these steps can be combined into a single transaction; this solution is about as good as it gets because this is an effectively-once message delivery implementation.
When it is not possible to combine these two steps into a single atomic operation, then one possible solution is that the persistence of the offset follows the state change persistence step. This two-step process, as shown in Figure 11, requires that the first step is idempotent. That is when the same message is processed more than once the outcome of the first step is the same.

Here is an example of a process that must be idempotent but is challenging to implement. Consider that the messages sent to the consumer are bank account deposits or withdrawals. The state of the bank account is altered and persisted when these deposit and withdrawal messages are processed. Obviously, it is essential that each bank account cannot be corrupted with duplicate deposits or withdrawals.
So how do we eliminate duplicate messages that cause cumulative state changes? The answer is that some evidence that a given message has been processed must be recorded as part of the cumulative state change’s transaction. This evidence could be persisting the current message offset in the same transaction. Another approach is to store all or part of the message itself so that incoming duplicate messages may be eliminated. One more strategy is first to log each incoming message, which then triggers the cumulative state change operations as a follow-on step. This final approach is known as event logging. We will look at this in detail in part 3 of this series.
Both the push and the pull at-least-once message delivery approaches are commonly used, and each has their strengths and weaknesses. Often, however, the pull approach tends to easier to implement.
There are some common features and considerations for both message delivery approaches. For both push and pull implementations the message producer is responsible for maintaining a list or queue or log of messages. When pushing messages, this list is used to retransmit messages that have so far failed to be delivered. When pulling messages, this list is used by the message consumer to retrieve and process pending messages.
Another common feature for both the push and pull approach is that the consumer may have to implement some form of idempotency. Idempotency is essential when the same message is delivered more than once to a message handler that performs state changes, such as a bank account message example previously discussed.
In Part 3, we will look at exactly-once message delivery. While theoretically, an exactly-once approach for message delivery is appealing once we look into the challenges and limitations I think you will see that the at-least-once approach is a more practical way to go.
