

The behavior of actors running in an actor system can be very dynamic. In some cases, the behavior is more organic than mechanical. Some actors systems are relatively simple and lightweight. On the other end of the spectrum, other actor systems are composed of hundreds to thousands to millions of individual running actors.
The lifestyle of different actors varies as well. Some actors live for a long time while others come and go in milliseconds. While some actors are relatively inactive other actors may be extremely chatty, sending and receiving messages as quickly as possible. Things get even more fun and interesting when actor systems are spread across a cluster of networked nodes.
When you implement an actor system, you may think that you know how your carefully crafted actors are going to behave. In most cases this is true, the majority of your actors do what they are expected to do. However, there are times when your actors may do things that you did not expect or anticipate.
Many things can cause actors to do the unexpected or to misbehave. It is one thing to design and implement a system for the happy state when everything is running fine. When there is plenty of CPU and memory capacity, no excessively long stop the world garbage collections, no network problems or the even more problematic network slowdowns, no failed cluster nodes, no unexpectedly large spikes in activity, everything may work well. But, as we well know, it is a tough world out there. Things do go wrong, bad things do happen, and that is when your finely crafted actor system may run into trouble.
It could be that you thought that you actors should behave in one way but something unexpected happens. Maybe there are more instances of some actors then you expected. Perhaps some actors are sending a lot more messages than you expected. One common problem is that some actors cannot keep up with the flow of incoming messages and a potentially lethal backlog of messages accumulates in mailboxes.
So how do you know what is going on in your actor system? One way is to use logging. You can embed various strategically placed log messages that provide some visibility into the happenings inside your actor system. Another way is to use monitoring. If you are a Lightbend subscriber, you have the option to use the Monitoring and Telemetry options that are included with your subscription. Telemetry is also free to use by anyone during the development phase.
Currently, the majority of the Telemetry capabilities are focused on capturing events and metrics from Akka systems. Monitoring for Scala and Lagom is also available, and new telemetry options are planned for future versions. Given the focus here is on Akka we will concentrate on Akka telemetry.
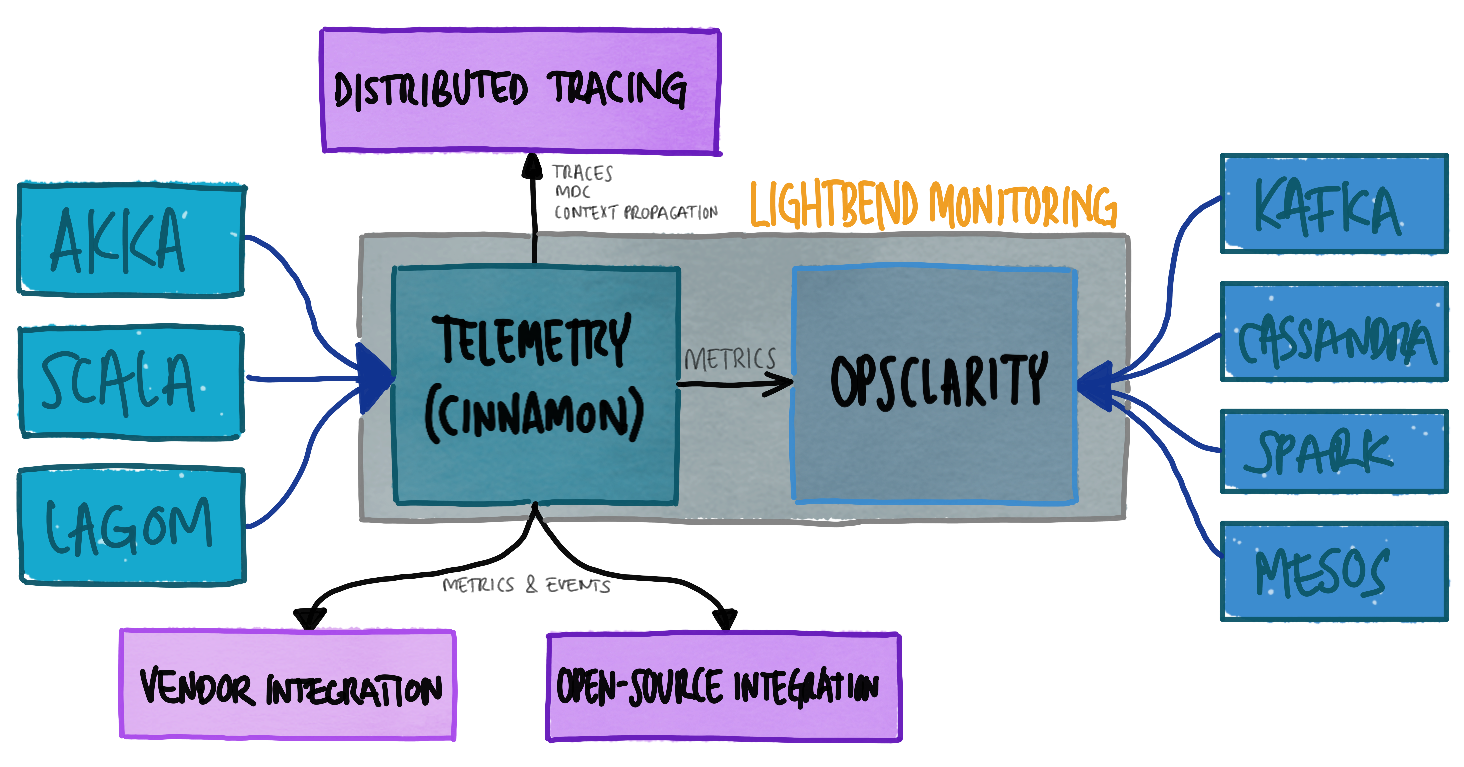
The above diagram in Figure 1 was copied from the Lightbend Telemetry documentation. As shown in this diagram, metrics and events are captured through instrumentation by a Java agent, which is also known as Cinnamon. To get a more detailed overview of how this works, please see the Introduction section of the Telemetry documentation.
The instrumentation provided covers a wide range of events and metrics. Here is a breakdown of the types of information that is available:
Please see the Akka Instrumentation documentation for the details.
Some events and metrics are often more interesting than others. For example, the actor metrics for the number of running actors and the mailbox size are often watched more closely than some of the other metrics.
The threshold events are a set metrics that are configured to trigger when specified threshold amounts are exceeded. For example, an actor class or group can be configured to trigger a threshold event when the mailbox size exceeds a specified level. These threshold events could then be set up to trigger alerts in some external support system.

In addition to the events and metrics distributed tracing is provided. As described in the documentation - A trace shows a dataflow or an execution path through a distributed system. Each span in the trace represents a logical unit of work. In the case of actors, each span represents the processing of a message by an actor. Tracing adds another view of actor behavior on top of the events and metrics.
The level of visibility provided by Akka Telemetry can be beneficial at all stages of the software development lifecycle. If you are a Lightbend subscriber, you have the option to use Lightbend Telemetry from the development stage and into production. Also, Lightbend Telemetry is free to use during development.
Getting started is easy. Just follow the directions provided in the documentation.
