

Everyone wishes the Scala compiler were faster. We’ve succeeded in making compilation feel faster by doing less of it: we’ve made big improvements to our incremental compiler, Zinc, and it is now available to users of all the popular IDEs and build tools.
But there are times when incrementality this just isn’t enough. When you’re building a clean checkout, or when you change a particular source file or dependency that is strongly connected in the dependency graph of your program, the raw performance of the compiler matters.
Even when the incremental compiler is working well for you, incremental compilation can require two or three small rounds of compilation, so small improvements in the performance of the compiler for small batches add up. And when it comes to maintaining your “flow”, seemingly small reductions in the interruptions can make all the difference in avoiding the urge to procrastinate!
In the run-up to the release of Scala 2.12.0, we found that one of our release candidates had a bad performance regression. It was caught before final release, but we realised that we’d been flying blind for too long, and set to the task of instituting automated benchmarking.
But, with this infrastructure, and the deeper insights into JVM internals that we’d gathered on our investigations, could we go further and make a meaningful improvement to compile times? The answer wasn’t clear: there have already been several efforts to improve performance (e.g 2.11.8 is about 15% faster than 2.10.6), so truly low hanging fruit might be rare. Furthermore, compilers are notorious for lacking the “hotspot”s of traditional application, so even after optimizing the most heavily used method, it can be hard to shift the overall performance. But we decided it was worth a fresh attempt.
Benchmarking is part science, part black art. JVM benchmarks must account for the effect of warmup (as the JIT compiler does its work), and non-deterministic performance due garbage collection and JIT compilation. Furthermore, we need to make sure we’re testing scenarios that relate to real-world workloads for the compiler.
Results are generated by running our benchmark suite (based on JMH). We measure the hot (warmed up JVM) and cold (first run of the compiler in a fresh JVM) performance for a number of bodies of source code. We’ve back tested some interesting parts of the history, and going forward, all merge commits will be benchmarked to help us spot performance regressions. We can also use this infrastructure to benchmark a pull request before we merge it.
To make sure we don’t overload our build farm, and that the benchmark server is used serially, these runs are scheduled by compiler-benchq with a little help from Jenkins. We have a dedicated physical machine for this purpose.
Results are publicly displayed in a dashboard https://scala-ci.typesafe.com/grafana
Let’s take a look at the results during the milestone builds before 2.12.0.
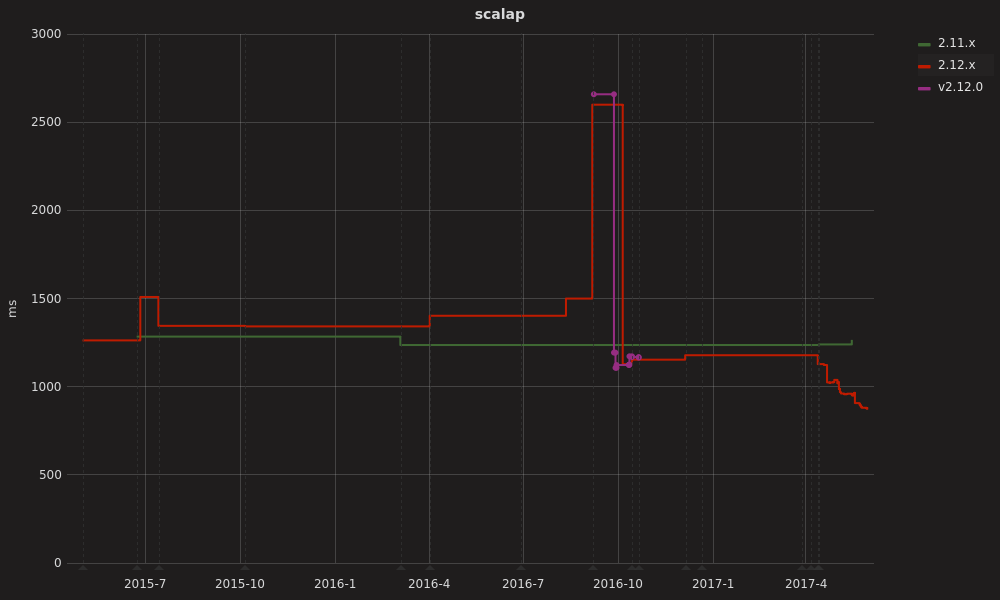
In July 2015 when we switched to the new implementation of the bytecode emitter and optimizer (“GenBCode”). In August 2016 things deteriorated further when we moved responsibility for desugaring fields to a dedicated compiler phase. Shortly after, as this phase took responsibility for desugaring nested objects, we hit rock bottom, with compile times of 2.5x the baseline.
In October 2016, we pieced together what had just happened: the new bytecode emitter was emitting synchronized slightly differently to Scalac 2.11 and Javac, and while it was technically valid it prevented JIT compilation. The effect of this was drastically amplified later when the reworked nested object translation changed the granularity of the methods that compute the value; whereas previously the synchronized block was in a small method that was only during object initialization, now the synchronized block had been inlined into the getter method called on every subsequent access. Every access to such an object ended up running through an interpreted method!
Fixing those issues turned out to be easy, but the experience of diagnosing them was something we didn’t want to repeat!
But even then, performance was still slightly worse than 2.11.8 for some benchmarks (even though the scalap benchmark pictured above had improved). We’d have some work to do in the 2.12 point releases to regain the ground that had been lost.
We’ve been looking at compiler performance with the help of any and every profiler we could find (YourKit, Java Flight Recorder, Oracle Developer Studio), stared into the Flame Graphs of compile runs and garnered insights into the JVM with JITWatch.
Armed with these insights, we’ve found a number of areas to improve. Around 20 performance oriented pull requests have landed so far, notably:
baseTypeIndex (a core method within subtype checking)List[A].subst(A, Int) => List[Int])The dashboard shows the effect of these changes landing in the build up to Scala 2.12.3.

We’re excited to report a significant speedup!
| Codebase | LoC | 2.11.11 | 2.12.3-pre | Factor |
|---|---|---|---|---|
| vector.scala | 932 | 301ms | 198 | 0.66x |
| better-files | 924 | 532ms | 371 | 0.70x |
| scalap | 2117 | 1239ms | 882 | 0.71x |
| scala compiler,library | 118k | 45.7s | 38.9 | 0.85x |
Smaller compile batches seem to profit the most. We believe this is because we’ve reduced some of the costs incurred the first time the type (e.g., List) is referenced from the sourced being compiled. Larger programs tend to have more call sites using a given type, so those first time costs aren’t as critical. Another theory is that larger programs require a larger working set of data, and experience proportionally more costs due to garbage collection and CPU cache misses. Further measurement and analysis is required to clarify the picture.
Note that the results discussed above are for hot performance.
The difference between hot and cold performance is enormous. For small batches of files, the first compilation can be 8x slower than the peak performance after JIT has done its work. JIT seems to take around 30s to reach reasonable performance, and another 30s to approach peak performance. Even on large batches of files, like the entire Scala library and compiler, a cold compile takes 67s as compared to the peak hot performance of 38s.
We recognize that this is a problem in and of itself, and are looking for ways to be more accommodating to JIT. But our initial focus has been on improving the hot performance.
So, how can you integrate a warmed up compiler into your toolchain?
IntelliJ supports use of an external compile server for Scala without installation of any other software. Scala IDE uses an internal compiler server running Zinc which stays alive as long as the IDE.
sbt users should start the a session and run successive compilations within the sbt shell, rather than issuing sbt compile repeatedly. Be sure you use the latest version of sbt – versions prior to 0.13.13 suffered from a bug that penalized performance by up to 30% by loading classes for each compile run that would cause the JVM’s JIT to deoptimize some parts of the compiler.
We recommend that Maven users install Zinc, start a Zinc server, and configure the maven-scala-plugin to use it.
While Gradle’s Scala plugin does support incremental compilation with Zinc, as of version 3.3 it does not support use of a compile server that runs longer than a single build.
We’d be grateful for help from existing Scala 2.12 users to test our nightly builds ahead of the release of 2.12.3, scheduled for July.
jardiff tool to confirm that the products of the nightly build of the compiler are identical to those that were generated by 2.12.2.We’d like to express our thanks for the help we’ve received during this process. Mike Skells and Rory Graves have provided code, advice, and independent testing of changes at important junctures. Pap Lőrinc lent a keen eye to review some changes. All of those three have also contributed performance improvements to the standard library.
Miles Sabin was first to alert us to the performance regressions in the 2.12 milestones, and helped validate our fixes.
We hope that our automated benchmarking will facilitate more contributions that improve performance. Read over our issue covering the performance theme and stop by scala/contributors on Gitter to share ideas and coordinate your efforts.
