


In this two-part blog series, we introduce the concepts and benefits of working with both spark-submit and the Kubernetes Operator for Spark. In Part 1, we introduce both tools and review how to get started monitoring and managing your Spark clusters on Kubernetes. In Part 2, we do a deeper dive into using Kubernetes Operator for Spark
Not long ago, Kubernetes was added as a natively supported (though still experimental) scheduler for Apache Spark v2.3. This means that you can submit Spark jobs to a Kubernetes cluster using the spark-submit CLI with custom flags, much like the way Spark jobs are submitted to a YARN or Apache Mesos cluster.
Although the Kubernetes support offered by spark-submit is easy to use, there is a lot to be desired in terms of ease of management and monitoring. This is where the Kubernetes Operator for Spark (a.k.a. “the Operator”) comes into play. The Operator tries to provide useful tooling around spark-submit to make running Spark jobs on Kubernetes easier in a production setting, where it matters most. As an implementation of the operator pattern, the Operator extends the Kubernetes API using custom resource definitions (CRDs), which is one of the future directions of Kubernetes.
The purpose of this post is to compare spark-submit and the Operator in terms of functionality, ease of use and user experience. In addition, we would like to provide valuable information to architects, engineers and other interested users of Spark about the options they have when using Spark on Kubernetes along with their pros and cons. Through our journey at Lightbend towards fully supporting fast data pipelines with technologies like Spark on Kubernetes, we would like to communicate what we learned and what is coming next. If you’re short on time, here is a summary of the key points for the busy reader.
What to know about spark-submit:
What to know about Kubernetes Operator for Spark:
The spark-submit CLI is used to submit a Spark job to run in various resource managers like YARN and Apache Mesos. It also allows the user to pass all configuration options supported by Spark, with Kubernetes-specific options provided in the official documentation. You can run spark-submit outside the Kubernetes cluster–in client mode–as well as within the cluster–in cluster mode. Below is a complete spark-submit command that runs SparkPi using cluster mode.
./spark-submit --master k8s://https://
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.kubernetes.namespace=spark \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-sa \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.container.image.pullPolicy=Always \
--conf spark.kubernetes.container.image=lightbend/spark:2.0.1-OpenShift-2.4.0-rh \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar
Let’s actually run the command and see what it happens:

The spark-submit command uses a pod watcher to monitor the submission progress. If everything runs smoothly we end up with the proper termination message:

In the above example we assumed we have a namespace “spark” and a service account “spark-sa” with the proper rights in that namespace. An example file for creating this resources is given here.
The CLI is easy to use in that all you need is a Spark build that supports Kubernetes (i.e. built with flag -Pkubernetes). There are drawbacks though: it does not provide much management functionalities of submitted jobs, nor does it allow spark-submit to work with customized Spark pods through volume and ConfigMap mounting. Not to fear, as this feature is expected to be available in Apache Spark 3.0 as shown in this JIRA ticket.
In client mode, spark-submit directly runs your Spark job in your by initializing your Spark environment properly. That means your Spark driver is run as a process at the spark-submit side, while Spark executors will run as Kubernetes pods in your Kubernetes cluster.
In cluster mode, spark-submit delegates the job submission to the Spark on Kubernetes backend which prepares the submission of the driver via a pod in the cluster and finally creates the related Kubernetes resources by communicating to the Kubernetes API server, as seen in the diagram below:

Now that we looked at spark-submit, let’s look at the Kubernetes Operator for Spark. The Operator project originated from Google Cloud Platform team and was later open sourced, although Google does not officially support the product. It implements the operator pattern that encapsulates the domain knowledge of running and managing Spark applications in custom resources and defines custom controllers that operate on those custom resources.
The Operator defines two Custom Resource Definitions (CRDs), SparkApplication and ScheduledSparkApplication. These CRDs are abstractions of the Spark jobs and make them native citizens in Kubernetes. From here, you can interact with submitted Spark jobs using standard Kubernetes tooling such as kubectl via custom resource objects representing the jobs.
On their own, these CRDs simply let you store and retrieve structured representations of Spark jobs. It is only when combined with a custom controller that they become a truly declarative API. A declarative API allows you to declare or specify the desired state of your Spark job and tries to match the actual state to the desired state you’ve chosen.
The Operator controller and the CRDs form an event loop where the controller first interprets the structured data as a record of the user’s desired state of the job, and continually takes action to achieve and maintain that state. Below is an architectural diagram showing the components of the Operator:

In the diagram above, you can see that once the job described in spark-pi.yaml file is submitted via kubectl/sparkctl to the Kubernetes API server, a custom controller is then called upon to translate the Spark job description into a SparkApplication or ScheduledSparkApplication CRD object.
The submission runner takes the configuration options (e.g. resource requirements and labels), assembles a spark-submit command from them, and then submits the command to the API server for execution. What happens next is essentially the same as when spark-submit is directly invoked without the Operator (i.e. the API server creates the Spark driver pod, which then spawns executor pods).
At this point, there are two things that the Operator does differently.
First, when a volume or ConfigMap is configured for the pods, the mutating admission webhook intercepts the pod creation requests to the API server, and then does the mounting before the pods are persisted. The exact mutating behavior (e.g. which webhook admission server is enabled and which pods to mutate) is controlled via a MutatingWebhookConfiguration object, which is a type of non-namespaced Kubernetes resource.
Second, there is an Operator component called the “pod event handler” that watches for events in the Spark pods and updates the status of the SparkApplication or ScheduleSparkApplication objects accordingly.
An alternative representation for a Spark job is a ConfigMap. The Kubernetes documentation provides a rich list of considerations on when to use which option. In this use case, there is a strong reason for why CRD is arguably better than ConfigMap: when we want Spark job objects to be well integrated into the existing Kubernetes tools and workflows. An example here is for CRD support from kubectl to make automated and straightforward builds for updating Spark jobs.
The SparkApplication and ScheduledSparkApplication CRDs can be described in a YAML file following standard Kubernetes API conventions. The detailed spec is available in the Operator’s Github documentation. The difference is that the latter defines Spark jobs that will be submitted according to a cron-like schedule.
Unlike plain spark-submit, the Operator requires installation, and the easiest way to do that is through its public Helm chart. Helm is a package manager for Kubernetes and charts are its packaging format. A Helm chart is a collection of files that describe a related set of Kubernetes resources and constitute a single unit of deployment. To install the Operator chart, run:
$ helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
$ helm install incubator/sparkoperator --namespace spark-operator
When installing the operator helm will print some useful output by default like the name of the deployed instance and the related resources created:
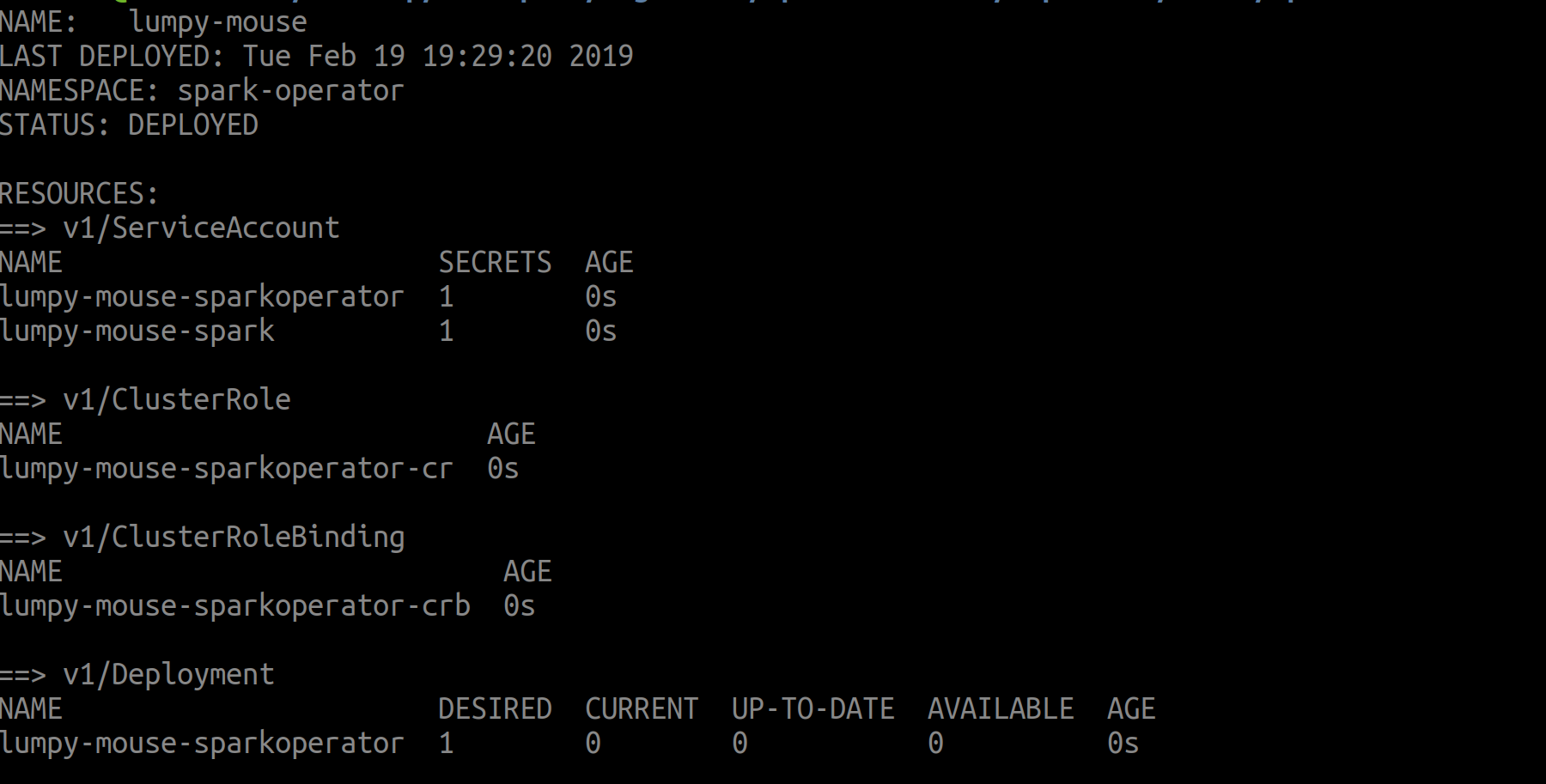
This will install the CRDs and custom controllers, set up Role-based Access Control (RBAC), install the mutating admission webhook (to be discussed later), and configure Prometheus to help with monitoring.
When you create a resource of any of these two CRD types (e.g. using a YAML file submitted via kubectl), the appropriate controller in the Operator will intercept the request and translate the Spark job specification in that CRD to a complete spark-submit command for launch. A sample YAML file that describes a SparkPi job is as follows:
pi.yaml:
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: spark
spec:
type: Scala
mode: cluster
image: "lightbend/spark:2.0.0-OpenShift-2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
driver:
cores: 0.1
coreLimit: "200m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: spark-sa
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
This YAML file is a declarative form of job specification that makes it easy to version control jobs.
Let’s submit the job:

Then we can verify that the driver is being launched at the specific namespace:

The SparkApplication controller is responsible for watching SparkApplication CRD objects and submitting Spark applications described by the specifications in the objects on behalf of the user. After an application is submitted, the controller monitors the application state and updates the status field of the SparkApplication object accordingly. For example, the status can be “SUBMITTED”, “RUNNING”, “COMPLETED”, etc.
Transition of states for an application can be retrieved from the operator’s pod logs. Here we see part of the state transition for the example application SUBMITTED -> RUNNING:

Same information can also be acquired by using kubernetes events eg. by running kubectl get events -n spark, as the Spark Operator emmits event logging to that K8s API.
Internally the operator maintains a set of workers, each of which is a goroutine, for actually running the spark-submit commands. The number of goroutines is controlled by submissionRunnerThreads, with a default setting of 3 goroutines. The Operator also has a component that monitors driver and executor pods and sends their state updates to the controller, which then updates status field of SparkApplication objects accordingly.
That brings us to the end of Part 1. Now that you have got the general ideas of spark-submit and the Kubernetes Operator for Spark, it’s time to learn some more advanced features that the Operator has to offer. In the second part of this blog post series, we dive into the admission webhook and sparkctl CLI, two useful components of the Operator. Click below to read Part 2!
