

NOTE
Akka Serverless is now Kalix. Learn more at Kalix.io.
Want to develop distributed, stateful applications while staying mindful of potential tradeoffs? Download your copy of Build Stateful Applications and get started running stateful applications in a simple and efficient way.
Function-as-a-Service (FaaS) is a nice abstraction of communication that does not equate to a true distributed and stateful offering. Here’s why: FaaS is great for certain tasks, such as parallel processing, orchestration, and stateless web applications, but the data processing is separate from the state of the application, which is always in the database.
While this separation of state from the data processing is nothing new for developers, a distributed stateful solution (a.k.a. “Stateful Serverless”) ensures optimal resilience, responsiveness, and elasticity when managing data in cloud-based distributed systems. In this post, we’ll uncover four unique technical benefits of building distributed stateful applications with Akka, a popular open-source runtime used by Global 5,000 companies like Starbucks, HPE, PayPal and more to handle their mission-critical systems.
FaaS is stateless. This means the state is contained in the database and it is up to the stateless function to access it.
Since distributed stateful applications combine the function and its state, we need a way of addressing the function by some key, as well as being able to locate it across application nodes and/or instantiate it on demand. Rather than a single stateless function that accesses some portion of data to perform its work, the stateful function represents some portion of a distributed state.
A good example would be customers shopping on an ecommerce site. Each customer would be represented by a unique key and both the state and the operations upon it are encapsulated in the function. If you have 1000 customers, then this means you have 1000 stateful functions running. Requests for a particular customer would be routed to the appropriate instance.
Here we can leverage tried-and-tested Akka actors, each having a unique address across the cluster, as well as Akka Persistence, which gives us the ability to co-locate actors and their state, sharded across the application cluster by some unique key. With this capability, current state and processing can be co-located and resolves the definition of stateful functions.
Domain entities, modeled as stateful functions, are great, but only part of the puzzle—albeit a very important part. A comprehensive distributed stateful solution needs some other characteristics, as well as clean ways of integrating between them in a decoupled manner.
Domain Projections, such as Command Query Responsibility Segregation (CQRS), point-to-point communication, broadcast, pubsub, Conflict-free Replicated Data Types (CRDTs), and ACID 2.0 are just the characteristics we need. These are all underpinnings we can leverage from Akka as well as familiar pubsub mechanisms such as Apache Kafka. This adds another dimension over FaaS, which only provides request/response.
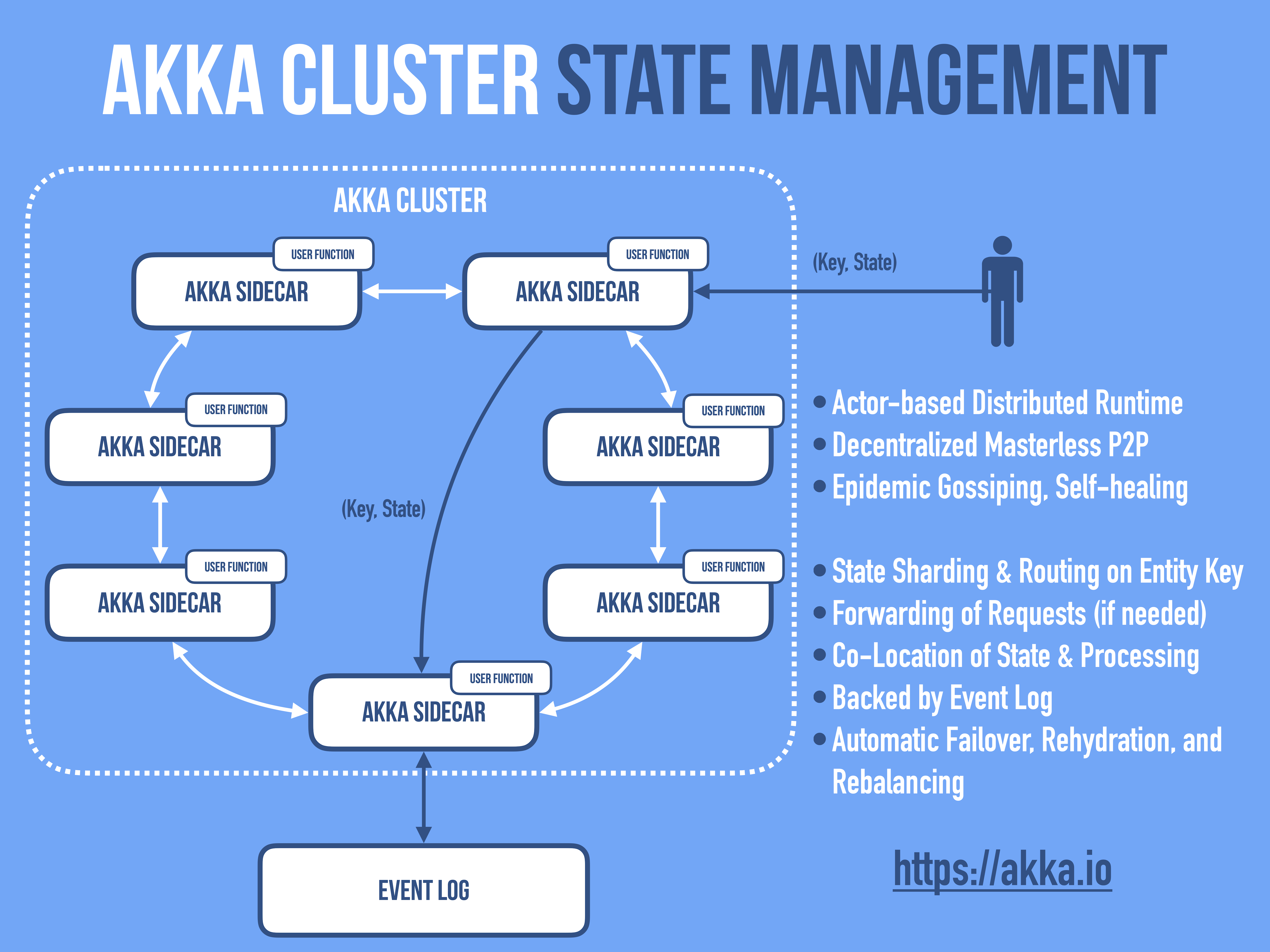
With FaaS, it’s not possible to reliably manage scale in a uniform manner, due to the black box problem between the functions and the unknown and unmanaged usage of data. We can solve this problem with distributed state, but it’s not without certain challenges. When the state is moved into the application, additional problems are presented, such as balancing functions across nodes, rapid elasticity, and speed of instantiation of new functions. In the image below, we see Akka Cluster as part of Cloudstate, our OSS distributed state management solution for Kubernetes. Using Akka Sidecars and gRPC, Cloudstate leverages Akka Cluster to maintain full resiliency at scale.

Akka Cluster manages sharded actors and ensures they exist on healthy nodes (and Kubernetes pods). Upon failure, actors are automatically moved, then re-instantiated using Akka Persistence backed by an immutable event log. With Akka in place, a framework with the necessary guarantees can be made, which is crucial to building reliable, stateful applications.
With FaaS, data access is a black box and its biggest limitation. Nothing is predictable.
Event-sourced events of reasonable size (domain-driven), presenting uniformity of the event log as well as CQRS (separating read and write requirements of the system). These constraints not only make distributed state possible, but satisfy performance, latency, and throughput requirements. Without event sourcing, the stateful function would be that black box. But what alternatives are available? Passing in the entire database to the functions? Unbridled database access? Neither of these options make sense when building stateful applications—or even stateless applications. The following shows how event sourcing is used with Akka, as well as Cloudstate.

Persistent Akka actors contain in-memory state and are uniformly distributed while being uniquely addressable in the cluster. Since each actor is a singleton, there is no contention as you usually get with a replicated database. There are also no concurrency concerns as each actor is bound by a mailbox. Each message is fully processed and state updated before handling the next request. This fulfills the dream of enabling the application layer to be fully functional, without needing to read a database in real-time. In addition, event sourcing is the lingua franca of Akka Persistence and allows serving state in a performant and consistent manner.
We should also show the unhappy path, rapid reinstantiation of functions using event sourcing.

As you can see, instantiating an event sourced function (domain entity in this case) is a matter of replaying all the events. In the case of many events, a state snapshot is used and the events since the snapshot are overlaid. No longer do we have a black box.
These four technical benefits produce some unique capabilities compared to what is typically offered by FaaS, such as functions with coarser granularity.
Imagine deploying an application as a collection of stateful functions that represent the domain, even applying Domain-driven design (DDD). Now a bounded context, encapsulating all of its functionality, can be deployed as a discrete unit. For example, a customer function would have all the necessary functionality, such as changeLastName and setHomeAddress, instead of deploying the functions within a customer separately. These customer functions have no value, since in DDD domain functionality is only accessed through the broader bounded context—and not shared or implemented in other contexts.
This was the first in a series of posts on distributed stateful applications. Keep an eye out for more content in the coming weeks containing useful polyglot examples.
Until then, please download your copy of Build Stateful Applications and get started running stateful applications in a simple and efficient way.
NOTE
Akka Serverless is now Kalix. Learn more at Kalix.io.