
Enterprise deployment of Reactive systems is no longer a fringe concept enjoyed by a handful of early adopters. According to the Reactive Manifesto, developing these message-driven, elastic, resilient and highly responsive applications is what’s fueling the new wave of systems that are deployed on everything from mobile devices to cloud-based clusters running thousands of multi-core processors. Users expect millisecond response times and constant uptime.
The largest enterprises like Twitter, Facebook, Google and Netflix are measuring their data in Petabytes—but even smaller companies are hungry to keep up with these big players, and strive to mimic the same quality of user experience.
But while Reactive application development is off to a roaring start and becoming mainstream, this leads to demands on Operations that are simply not met by yesterday’s software architectures and technologies. The pressure facing enterprises to manage resilient, responsive systems is brutal, yet most existing technologies available today are not designed to deploy and manage Reactive systems running on clusters. It’s due to this fact that Operations face a higher risk of downtime by using inappropriate tools/practices at a time when being unavailable is more costly than ever. So why is this happening? Well, it's not 2005 anymore–and why that's a problem for Operations is explained just below...
The rapid cycle of technological innovation is troubling for enterprises, namely in how they structure their systems and business models in the long term. If we look back 10 years to 2005, you’ll remember that we didn’t have the iPhone, Facebook, Twitter, Netflix streaming, Kindle, App Store, Spotify or Big Data tools. Enterprise architectures looked something like this:

In 2005, the average household of consumers would have had one or two computers—a desktop and super-heavy laptop, let’s say—which would connect to applications running on one or two redundant servers. Internet connectivity wasn’t especially fast, and applications weren’t especially fast. Let’s face it, by today’s standards nothing was really that fast. And most of us were fine with it—back then.
Today, however, we cannot tolerate an additional few seconds of delay (side note: I'm not clear on whether there is any record of the first internet-speed related crime of passion, but I can predict we'll one day see this). Jumping forward to 2015, we see how the network topology of enterprises has evolved to meet consumer demands:

What happened in the last 10 years? Well, this very same household now has multiple devices per person—all of which may use different protocols and platforms. Multiple laptops, mobile phones, tablets and e-readers require instant response times and constant availability. Now we have 10 or more devices connecting to multiple application server instances, all needing a high level of responsiveness and fault-tolerance.
Tremendous, exponential growth over the last decade was basically caused by the new explosion in mobile devices on top of everything else evolving. This continues to put a lot of pressure on internet services and enterprise systems, but some think that an even larger wave is still to come in the Internet of Things (IoT). Gartner predicts that the IoT ecosystem will lead to the existence of over 25 billion connected devices by 2020. This is what enterprise architectures will need to look like in order to survive then:
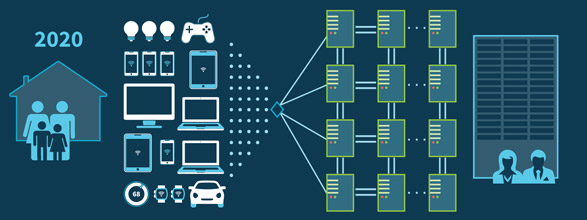
Naturally, the connected “things” we use today will look as advanced in 2020 as an iPhone 3G does in 2015. Enterprises will build new systems—and refactor many old ones—in order to accommodate this new generation of intelligent wearables, home appliances, health devices, automotive elements, lights, windows and door locks that will join up with the huge base of mobile devices. Many tens of devices per household will connect constantly to tens or hundreds of servers, 24 hours a day, 365 days a year. Now you can see why Operations is having trouble sleeping at night (when they aren't up manually deploying new systems at midnight).
If this is to be our near future, then we believe that a coherent approach to systems architecture is needed, and that all necessary aspects are already recognized individually: in Reactive systems that are message-driven, elastic, resilient and responsive. Enterprises are encouraging their development teams to embrace Reactive system architectures based on microservices.
However, new system architectures require new approaches and little attention has been paid to how Operations is supposed to deploy and manage Reactive systems based on distributed, microservice-based architectures–especially when the tools Operations use now are usually purposed with doing something else altogether (i.e. deploying single apps on monolithic servers).
And it is this issue that raises three specific concerns that we believe contributes to difficult, error-prone deployments of Reactive systems:
In the next post, we'll dig in deeper to these issues, what they mean for Operations, and how enterprises as a whole cannot ignore the next wave of applications running on those billions of connected things. Just bridging the imagination gap right here is enough to start helping Operations, who are already beginning to sleep fitfully, plagued by nightmares of one monolithic server crashing after another on Black Friday...while the whole company watches...
