


With the recent release of Cloudflow 2.1, we at Lightbend have reorganized the way that Akka Data Pipelines and Cloudflow interact with Spark and Flink to put more control into the hands of our users. This is already available as an experimental feature in Cloudflow 2.1 with plans to make it permanent in the future.
If you weren't aware, Akka Data Pipelines is the enterprise packaging of our OSS Cloudflow project, which provides Lightbend Telemetry for insights into your running system as well as world-class support and guidance from the Lightbend engineering teams.
A few months ago, as our Akka Data Pipelines customers started to use larger and larger workloads in production, we realized that our faith in the integration with third-party operators may have been misplaced. We needed a way to interact with Flink that was more robust and production capable than we currently offer. We wanted to allow our customers to completely manage Flink and still create interconnected Cloudflow applications.

To that end we came up with cloudflow-contrib which allows Flink to be set up in a way that meets the demands of the customers.
Our plan is to release this via a three-step release process: Experimental feature, Transitional feature, and finally the removal of support for the older third-party-operator way of managing Flink.
Along with Flink we determined that Spark support would also benefit from this change and have applied those changes at the same time.
Our first priority was to preserve a seamless integration and a smooth transition to the new model. At the same time we felt the need to give more control to the users to let them achieve higher levels of availability and operational efficiency.
The Cloudflow features we wanted to have continuity with are:
Cloudflow-contrib responds to those requirements being an external and community maintained set of libraries and helpers to put Cloudflow's external integrations in control of the users.
The high level Cloudflow design has changed a bit to allow for these changes, where we had before:
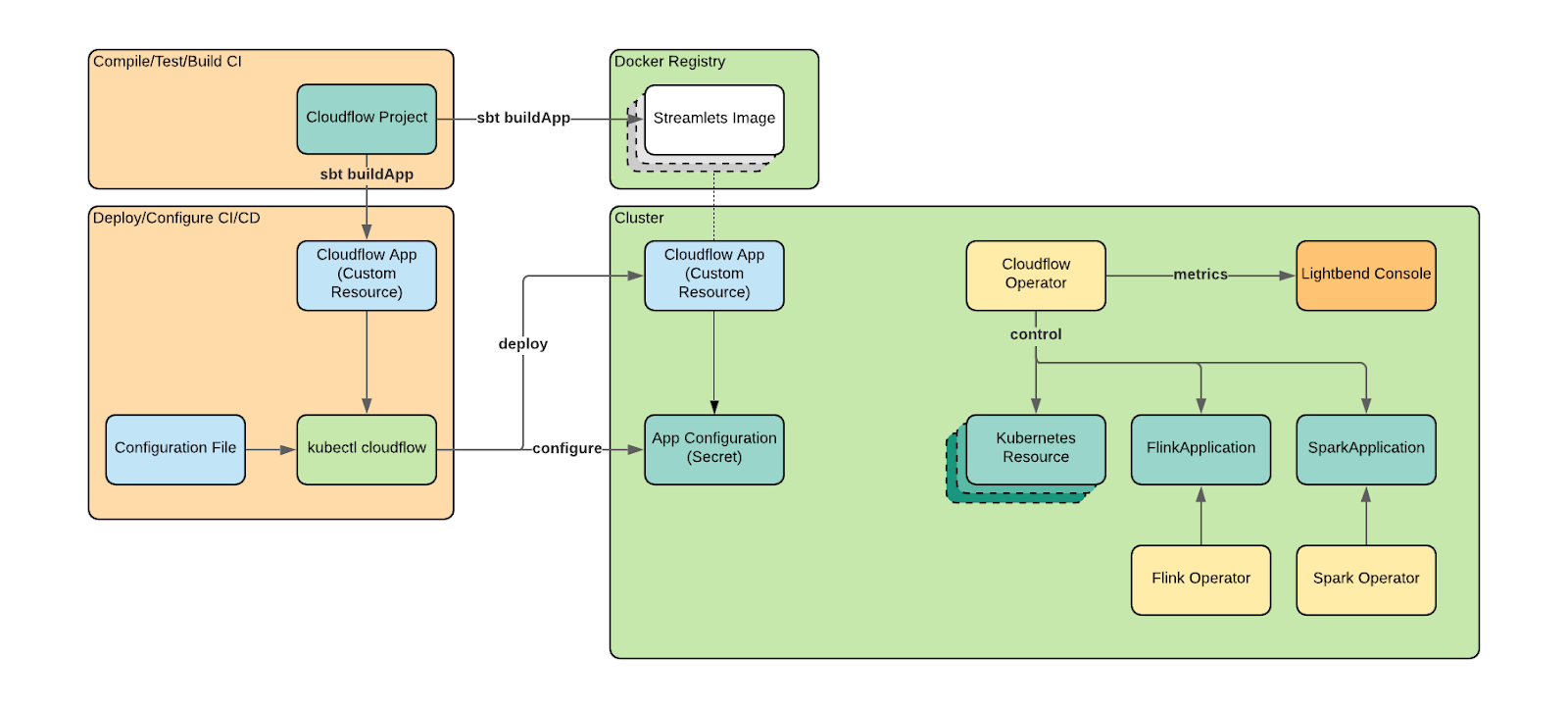
We now have a new interoperability scheme using cloudflow-contrib:

The Cloudflow operator doesn’t write CustomResources anymore for Flink and Spark operators, leaving space for the user to fill the gap. The operator will own and manage only the Akka streamlets while we provide customizable example-scripts to deploy and handle the lifecycle of Flink and Spark applications.
As of today the available examples are covering the integration with:
The following steps will allow you to start using and taking advantage of this new integration scheme. You can also find two Cloudflow example projects that show everything in detail.
Deploy the Cloudflow operator disabling the legacy support for Flink and Spark such as:
helm upgrade -i cloudflow cloudflow-helm-charts/cloudflow \
--version "2.1.0" \
--set cloudflow_operator.jvm.opts="-Dcloudflow.platform.flink-enabled=false -Dcloudflow.platform.spark-enabled=false -XX:MaxRAMPercentage=90.0 -XX:+UseContainerSupport" \
--set kafkaClusters.default.bootstrapServers=cloudflow-strimzi-kafka-bootstrap.cloudflow:9092 \
--namespace cloudflow
Start to use cloudflow-contrib sbt plugin into your project.
Add to your plugins.sbt file:
addSbtPlugin("com.lightbend.cloudflow" % "contrib-sbt-flink" % "0.1.0")
addSbtPlugin("com.lightbend.cloudflow" % "contrib-sbt-spark" % "0.1.0")
Change the relevant projects to use the new plugins, for Flink:
.enablePlugins(CloudflowApplicationPlugin, CloudflowFlinkPlugin, CloudflowNativeFlinkPlugin)
.settings(
baseDockerInstructions := flinkNativeCloudflowDockerInstructions.value,
libraryDependencies ~= fixFlinkNativeCloudflowDeps
)
And for Spark:
.enablePlugins(CloudflowApplicationPlugin, CloudflowSparkPlugin, CloudflowNativeSparkPlugin)
.settings(
baseDockerInstructions := sparkNativeCloudflowDockerInstructions.value,
libraryDependencies ~= fixSparkNativeCloudflowDeps
)
Now you can build you Cloudflow application with the usual command:
sbt buildApp
Deploy the application to your cluster skipping the Flink and spark CLI’s checks:
kubectl cloudflow deploy your-application-cr.json --unmanaged-runtimes=flink,spark
Now the Cloudflow operator will immediately start to take care of all the Akka Streamlets and you would need to deploy Spark and Flink streamlets.
The status is reflected by the kubectl cloudflow status command:

In the examples-scripts folder there are a few naive implementations of the deploy command for Flink (using the native Kubernetes CLI) and spark (using both spark-submit and the Google operator).
The first time make sure you create the necessary service account (e.g. by running the setup-example-rbac.sh script) for details refer to upstream documentation for Flink and Spark. And finally cd into the relevant directory (e.g. flink/deploy) and run the script to deploy the streamlets to the cluster:
./deploy-application.sh app created-service-account
Repeat this last step for all of the runtimes (e.g. Flink and Spark) and you end up with a perfectly working Cloudflow application!
In the Cloudflow project we discovered the challenges and tradeoffs of deep integration with multiple operators. With the feedback from our customers and team we feel that we now have a great way to address those concerns.
Cloudflow-contrib proposes a new approach to operating heterogeneous microservices applications with Cloudflow, our first use-cases already show really positive results achieving increased resiliency and stability!
Thanks for taking the time to read about these changes and we would love to hear from you with suggestions and comments in our discussion forum or via Twitter @Lightbend. We also recommend you check out the Akka Data Pipelines (and Cloudflow) documentation, as well as this brand new Akka Data Pipelines IoT Tutorial.
