
The transactional CRUD update-in-place approach has served most enterprise use cases well for decades. CRUD can still be a reasonable option within a microservice that owns its data exclusively or for services that act as endpoints where data is mainly read, such as an email service.
As part of the trade-off for achieving reactive characteristics, complexity arises when the data needs to be shared among multiple services. You can’t easily do joins across services to get a consistent view of the data. One solution is to use an additional event stream to propagate events to a third-party service. The third-party service can do joins of information from multiple services and satisfy read-only queries. This avoids tight coupling resulting from trying to enforce consistency across microservices.
Transactions can’t span hosts without coordination. Distributed transactions incur high latency with increased possibility of failures — the opposite of microservice goals. In addition, operations that block all the way down to the database often do not take full advantage of multi-core architectures.
The focus on events during system design opens up possibilities of persisting data in different ways. The facts generated at runtime offer a natural resource that can be easily tapped. For example, think about persistence in the model of a bookkeeping ledger, where all events are recorded. Rather than overwriting an existing entry with a new value (the CRUD model), a bookkeeper creates a new entry that represents the changed value.
Microservice systems can imitate this by keeping a log of events in the order in which they come in. An event log provides reliable auditing and simplifies debugging. When the log is provided by a messaging service, other microservices and legacy applications can subscribe to events of interest. And, in the case of failure, it is possible to replay the log at any time. This pattern is referred to as event sourcing.
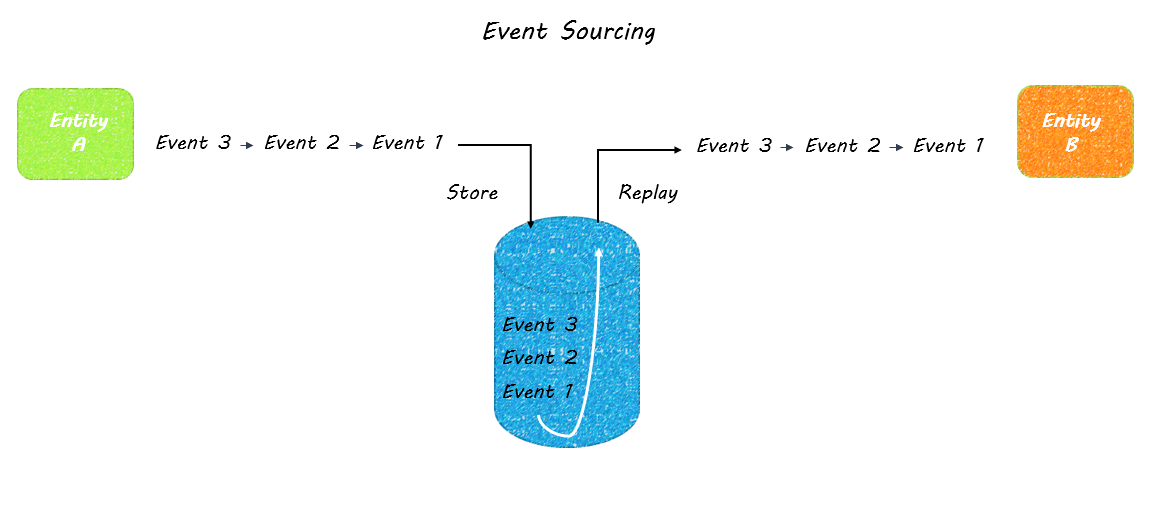
Event sourcing can provide insights that are lost in traditional systems where data is overwritten. For example, on an ecommerce website, you could track which products are most often put in the cart and then removed. This information would not be available in shopping carts implemented as simple update in place persistence. In a complex microservices system, queries often need to join data in ways not supported by the initial domain model. This is especially true when the model is event sourced and using CQRS to separate the read and write models of a system.
In less than 15 minutes:
In less than an hour:
Really dig in: